Why I wrote this
A few months ago I sat down and tried to actually understand delivery guarantees end-to-end - outbox, inbox, idempotency, XA, sagas, the whole pile. The thing none of the writeups did for me was separate these patterns from each other. They get name-dropped in the same paragraph, the names overlap, and the topic ends up feeling more tangled than it actually is.
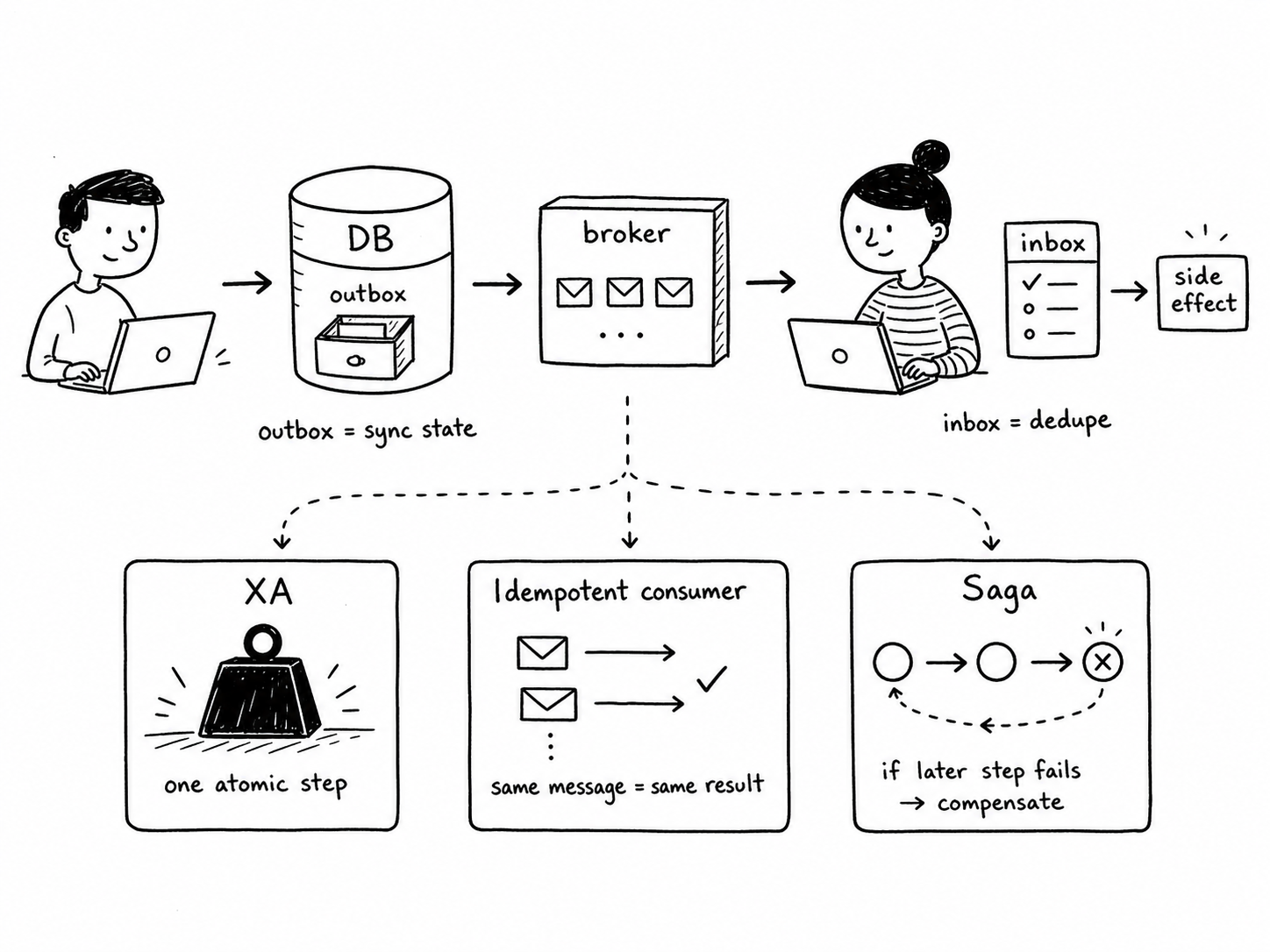
What unlocked it for me was forcing each pattern into its own little box and writing on the lid what question it answers. This one is about state sync. This one is about dedup at the consumer. This one is about rolling back if you’ve already done something. This one is the heavy hammer that tries to do all of it atomically. None of the patterns are individually hard. The naming is what’s hard. So this article is essentially the box-per-pattern map I wish I’d had when I started, plus the framing that, once it landed, made the rest fall into place.
The framing, in one go: a service has two stores it cares about, its database and its message broker (Kafka, RabbitMQ, NATS, doesn’t matter which). When something happens, both of those stores need to reflect it. The DB has to record the new state, and the broker has to carry the corresponding event to whoever is downstream. Two separate systems with two separate sets of failure modes, and no atomic “do the side effect everywhere at once” primitive across them. Pretty much every backend application is a CRUD, just at varying complexity and with a delayed action. Half-joke, but the picture really is that simple.
Everything below is about coordinating side effects across those two stores when each of them can fail independently. That’s why two-phase commit and XA exist (the classical answer: couple them with a distributed transaction). It’s also why outbox, inbox, idempotency, and sagas exist (the modern answer: accept that the systems are separate and reconcile at the application layer). Exactly-once isn’t real at the wire. It can only be real as an outcome.
The architectural side, exchanges/queues vs. topics/partitions, push vs. pull, when to pick which broker, is in the companion piece, Kafka vs RabbitMQ: models, architectures, and when to use each. Here the focus stays on guarantees.
Delivery semantics: at-most-once, at-least-once, exactly-once
Delivery Semantics: In distributed messaging, there are three levels of delivery guarantee:
- At-most-once: Messages are never delivered more than once, but some may be lost (no retries on failure).
- At-least-once: No messages are lost (failed deliveries are retried until success), but duplicates can occur.
- Exactly-once: Each message is processed exactly one time - none lost and none duplicated. This is the most desirable semantic, often called the “holy grail” of messaging.
In an ideal exactly-once scenario, every message sent by a producer is received and processed one and only one time by the consumer. However, in practice exactly-once delivery is extremely difficult (almost impossible) to achieve in a distributed environment. The reason - to circle back to the framing above - is that side effects cannot be coordinated for free across networks, brokers, and consumers that can each fail independently.
Why exactly-once is hard
Consider that a consumer might receive a message and start processing it, then crash or lose connectivity before acknowledging it. The broker (e.g., RabbitMQ) will redeliver the un-acked message to another consumer (or the same one on restart) to ensure it’s processed. This guarantees at-least-once delivery, but if the first attempt actually succeeded (e.g., triggered a side effect) before crashing, that side effect could happen twice. Exactly-once delivery would mean designing a system such that even in these failure scenarios, the effect of each message happens only once. As Jack Vanlightly notes, when a message involves multiple steps (application logic, database writes, caches, etc.), “can we really guarantee exactly-once processing? The answer is no.” Without special measures, the system may need to deliver a message twice to successfully process it once (after a failure).
Idempotency and “effectively” exactly-once end-to-end
Because true exactly-once end-to-end is so challenging, practical systems aim for “effectively exactly-once” semantics. This usually means designing message processing to be idempotent or doing duplicate detection so that processing a message twice has the same effect as processing it once. In other words, we accept that duplicates might occur at the messaging level, but we handle them such that the outcome is as if each message was processed only once.
- Idempotent Operations: An operation is idempotent if performing it multiple times has the same result as performing it once. For example, setting a record’s status to “processed” is idempotent (repeating it doesn’t change the final state), whereas sending an email or charging a credit card is not idempotent by default (doing it twice doubles the effect). Idempotent message processing means your consumer can safely reprocess the same message without unintended side effects. This often requires including a unique message ID and tracking which IDs have been processed, so duplicates can be detected and ignored. For instance, the Idempotent Consumer pattern uses a datastore (like an extra table of processed message IDs) to skip or merge duplicate messages. As one engineer quipped, “The way we achieve exactly-once delivery in practice is by faking it. Either the messages themselves are idempotent… or we remove the need for idempotency through deduplication.” In financial services, this approach is critical - e.g. payment APIs like Stripe require clients to send a unique idempotency key with each request. The server stores these keys and if a duplicate request comes in (say due to a retry or user double-click), it recognizes the key and prevents a double charge. This ensures that even if a payment request is processed twice internally, the customer is charged only once.
- Deduplication stores: the obvious mechanic is to keep a record of processed message IDs and check it on every new message. The pattern has its own name and its own section below - inbox - so for now just hold the idea that idempotency at the consumer is usually backed by a small persistent store keyed by message id.
In summary, achieving exactly-once effects relies on application-level cooperation. The messaging layer alone cannot guarantee end-to-end exactly-once delivery across arbitrary services. Instead, the combination of at-least-once messaging + idempotent processing = “effectively” exactly-once in outcome. We design consumers and downstream systems (databases, APIs) to tolerate repeats. A pithy rephrasing is: Exactly-once = At-least-once + Idempotency.
The Outbox pattern: state sync, not deduplication
Outbox is the one I want to slow down on, because it’s the pattern I personally got wrong the first time, and most explanations I’ve seen actively push you toward the wrong model. I assumed outbox was about idempotency and dedup. A lot of people do. The same confused framing turns up everywhere - Habr, Medium, blog comments, even some otherwise careful writeups. It’s not what outbox is about. Outbox is about state synchronization between the database and the broker. That’s the whole job.
Recall the picture from the intro: two stores, the DB and the broker. The thing outbox solves is the gap between writing to the database and publishing the corresponding event. Without outbox, the canonical bug looks like this: I commit a row to the DB, the process dies before the publish, and the rest of the system never learns anything happened. Or the inverse: I publish first, fail to commit the row, and now everything downstream is reacting to a state that doesn’t actually exist in my DB.
Outbox closes that gap by piggy-backing the event onto the same DB transaction. You write your business row and an “outbox” row in one atomic commit. A separate relay process then reads the outbox table and publishes the events to the broker. If the relay crashes mid-way, it just picks up where it left off; the outbox rows are still sitting in the DB, they didn’t go anywhere.
What outbox guarantees, then, is that every committed DB change will eventually lead to a published event, and no event is ever published for a change that wasn’t committed. What it does not guarantee is that the published event arrives exactly once at the consumer. The relay can retry, the broker can fan out, duplicates are absolutely on the table. Outbox sits at one specific layer of the side-effect coordination problem: DB and broker agreeing about whether the thing actually happened. The consumer side - making sure that processing a duplicate doesn’t double-charge a card or double-send an email - is a separate layer entirely.
The Inbox pattern: deduplication at the consumer
That separate layer is the inbox pattern. Inbox is where idempotency and deduplication actually live, and it’s the natural counterpart to outbox in exactly the way the names suggest: outbox makes sure events go out in lockstep with state, inbox makes sure events come in without being applied twice.
The shape is straightforward. When a consumer receives a message, before applying any side effect, it checks an “inbox” table (or any deduplication store) keyed by the message id. If the id is already in there, the consumer skips the side effect and just acks. If not, it performs the side effect and records the id in the inbox table, ideally inside the same DB transaction as the side effect itself, so that “we did the work” and “we marked the message as processed” cannot drift apart.
That’s the idempotent-consumer pattern with a name attached. It’s what makes “at-least-once messaging + inbox = effectively exactly-once” actually hold in practice. The broker is allowed to redeliver freely; the inbox eats the duplicates.
The whole thing in one picture
At this point the patterns start clicking into a shape, and the shape is what I find easier to remember than any individual definition. The whole topic comes down to two questions, asked in order:
- Are the two stores telling the same story? That’s the state-sync question, between the DB and the broker.
- Once the event is on the wire, how do we make sure the side effect at the consumer fires once, and only once? That’s the dedup-or-undo question.
Each question has a small set of architectural answers, and that’s the whole map:
flowchart TD
A["<div>Service<br/>change</div>"] --> B["<div>DB + broker<br/>must agree</div>"]
B --> C{"<div>State<br/>sync?</div>"}
C -->|"app layer"| D["<div>Outbox<br/><span>DB tx + relay</span></div>"]
C -->|"global atomicity"| E["<div>XA / 2PC<br/><span>coordinator</span></div>"]
D --> F["<div>Broker event<br/><span>may be duplicated</span></div>"]
F --> G{"<div>Side effect<br/>fires once?</div>"}
G -->|"skip duplicate"| H["<div>Inbox<br/><span>idempotent consumer</span></div>"]
G -->|"undo outcome"| I["<div>Saga<br/><span>compensation</span></div>"]
G -->|"inside Kafka"| J["<div>Kafka transaction<br/><span>offsets + output</span></div>"]
classDef source fill:#fbfaf5,stroke:#171717,color:#171717;
classDef question fill:#fff1bb,stroke:#171717,color:#171717;
classDef pattern fill:#fffaf0,stroke:#171717,color:#171717;
class A,B,F source;
class C,G question;
class D,E,H,I,J pattern;
XA sits on the top branch by itself because it’s trying to collapse both questions at once: keep the two stores atomic, and have the consumer-side effect ride inside that same atomic envelope. That’s why it’s the heavy hammer; it’s structurally one level higher than the others. Everything else accepts that the two stores are separate and answers the two questions independently.
The rest of the article is, more or less, a zoom-in on each node.
XA Transactions and distributed two-phase commit
What about using distributed transactions to achieve exactly-once directly? XA is the standard for two-phase commit across multiple resources, say a database and a message queue. A global coordinator ensures that either all operations across the participating systems commit, or all abort together, which makes a multi-step operation atomic across them. With XA you could enroll a message broker and a database in the same transaction so that acknowledging a message and updating the database happen as one unit; if either part fails, the whole transaction rolls back and you don’t ack the message without the DB write, or vice versa. In theory this prevents the canonical duplicate scenario (process message → write DB → crash before ack): if the app crashes after the DB commit but before the broker ack, the transaction is rolled back, the DB write is undone, the message stays un-acked and gets retried, no duplicate effect.
The catch is the price. A two-phase commit needs multiple round trips and disk flushes to prepare and commit on every participant, which adds real latency and turns the coordinator into a contended hot spot in high-throughput systems. Every participating resource has to actually support XA and play well with a transaction manager, which in practice not all of them do. And if the coordinator itself fails at the wrong moment, you can be left needing manual recovery just to figure out what state the world is in. That bundle of costs is why most modern architectures route around XA in favour of the outbox + inbox + idempotency story.
Saga: when you can’t avoid the side effect, undo it instead
A saga is what you reach for when you can’t make a multi-step business operation atomic, but you still need it to either complete fully or appear as if it never happened. The shape is a sequence of local transactions, each paired with a compensating action that semantically undoes its effect. If step 4 fails, you run the compensations for steps 1-3 in reverse, and the world ends up roughly back where it started.
The cleanest way to contrast saga with XA is this: XA tries to never let the wrong state exist; saga lets the wrong state exist briefly, then walks it back. That’s why saga is operationally cheaper (no global coordinator, no two-phase commit) but logically harder (you have to design a sane compensation for every step that has a side effect).
The honest caveat, and the part that ties saga right back to the side-effects framing, is that compensation is not rollback. If you’ve already sent an email, the compensating action is sending an apology email, not unsending the original. If you’ve already shipped a package, the compensation is generating a return label. Side effects are still side effects; saga just gives you a structured way to issue more of them in the opposite direction.
Two flavours worth recognising by name. In an orchestrated saga, a coordinator service drives the steps and decides when to compensate. In a choreographed saga, services react to each other’s events with no central driver. Same idea, different blast radius when something goes wrong.
On the diagram above, saga lives on the “already applied, undo it” branch, complementary to inbox on the “don’t apply twice” branch. Both are answers to the same downstream question - how do we make the consumer-side outcome look exactly-once - they just sit on opposite philosophical ends of it.
CAP Theorem (and is it relevant here?)
A small personal aside before the textbook bit, because CAP is one of those things that, when I was first poking around distributed systems, kept showing up everywhere - every article on databases, every post on consensus, every talk on storage - usually as a glancing reference to consistency, availability, partitions without enough context for it to actually stick. The theorem itself was not the problem. The problem was that I had nowhere in my head to put it. The patterns above (two stores, outbox, inbox, idempotency, XA) are exactly that “somewhere”.
So why am I dragging CAP into an article that is technically about messaging and delivery semantics, not replicated storage? Not by accident. CAP is, to my eye, the cleanest one-sentence statement of the underlying trade-off that every pattern above is, in some form, paying for. Once you see CAP through that lens, the same shape becomes visible everywhere - in event-driven architectures, in stream processing, in any system where multiple components have to agree on something across an (unreliable) network - even if a purist would prefer we stay strictly inside the messaging box.
The CAP theorem is a fundamental principle in distributed systems, though it’s not directly about messaging semantics. CAP stands for Consistency, Availability, and Partition Tolerance. It states that a distributed system cannot guarantee all three at the same time - you can only have two out of three. In the presence of a network partition (communication break), the system must choose between being consistent (all nodes agree on the same data even if it means some parts of the system aren’t available) or available (the system continues to respond to clients, possibly with stale or differing data between partitions).
How does CAP relate to exactly-once delivery? Well, if you think of delivering a message “exactly once” as a form of consistency (the state of “message processed” is consistent across components - no duplicates, no misses), you might have to sacrifice availability to achieve it. For example, to avoid duplicates, you might require a transaction with a database or a coordination service. If a network partition or failure occurs during that process, an AP (available but not consistent) system might choose to deliver the message to another node (ensuring availability but risking a duplicate), whereas a CP (consistent but not fully available) approach might pause processing that message until it’s sure whether the first attempt succeeded or not (trading availability/performance for consistency). In effect, trying to guarantee exactly-once across distributed components often means introducing coordination and waiting, which can reduce availability or throughput. This is why many systems favor eventual consistency with idempotent design - they accept that under partitions or failures the system might do things twice or out-of-order, and instead mitigate the effect (e.g., deduplicate later) rather than block everything waiting for perfect global coordination.
In summary, CAP reminds us that in a distributed world you can’t have it all. If you attempt to build a strictly consistent exactly-once delivery mechanism in a distributed system, you will likely do so by compromising on availability (e.g., waiting on transactions, or halting on uncertainty). Conversely, if you prioritize availability (the system always responds and processes), you must handle the reality that duplicates or lost messages (inconsistencies) can happen during failures. Thus, CAP isn’t directly invoked when we talk about messaging guarantees, but it underlies the trade-offs. Most messaging systems (Kafka, RabbitMQ, etc.) choose availability and partition tolerance over absolute consistency of delivery count - they provide at-least-once delivery and leave it to the application to reconcile duplicates, rather than halting the system to avoid a duplicate. This design gives robust throughput and availability, at the cost of requiring idempotent handling for true exactly-once effects.
RabbitMQ vs Kafka: exactly-once semantics and idempotence
Both RabbitMQ and Kafka were designed primarily around at-least-once delivery, but they approach exactly-once guarantees differently (and in RabbitMQ’s case, it’s basically left to the user). Let’s compare:
RabbitMQ (and Traditional Message Queues): RabbitMQ provides at-most-once and at-least-once delivery modes, but it does not natively support exactly-once delivery to consumers. This is due to its push-based model and complex routing - once a message is acknowledged and removed from the queue, RabbitMQ itself doesn’t keep track of it anymore, and it cannot coordinate across multiple queues or consumers to eliminate duplicates. The RabbitMQ documentation and community best practices say that if you need “exactly once”, you should implement it by making your consumers idempotent and your processing transactional where needed. In practice:
- RabbitMQ offers message acknowledgments and durability to ensure at-least-once delivery (no message is lost; if a consumer fails before ack, the message will be redelivered). But if a message is processed and acknowledged, RabbitMQ assumes it’s done. If that processing actually partially failed on the application side (say it succeeded in one step but failed in the final step without crashing, etc.), RabbitMQ doesn’t know - it won’t requeue that message once acked. Therefore, the application must handle such logic.
- There is a “transactional channel” feature in RabbitMQ (and publisher confirms) which can ensure a message publish is atomic and persisted before proceeding. However, RabbitMQ’s transactions apply to publishing to and consuming from the broker itself - for example, you can publish multiple messages in a transaction and commit them together, or consume and ack messages as a transaction. This can help in certain workflows (like ensure a batch of messages is acknowledged only if all are processed). But it does not automatically extend to external systems like your database.
- Idempotent Consumer Pattern: As discussed, the common approach for RabbitMQ exactly-once processing is to include a unique identifier with each message and have the consumer check a store (like a database or cache) to see if that ID was seen before. If yes, skip processing (and just ack). If no, process the message, and record that ID as processed (ideally in the same transaction as any other side effect). Only after successful processing do you ack the message. This way, if a message is redelivered, the consumer will see the flag and not duplicate the side effect. This requires that your side effects (e.g., writing to a DB) and the recording of the message ID can be done atomically - often the easiest way is to perform the side effect in a database and use the message’s unique ID as a primary key or part of the record. If a duplicate message comes, the DB operation will either fail a uniqueness check or be a no-op because the same primary key is already there. (Many fintech systems use this technique; for instance, a payment message might contain a transaction ID that the processing service uses as the DB transaction primary key - if the same ID comes again, the insert/update will indicate it’s a duplicate and avoid double-processing.) This is the inbox pattern in disguise.
Kafka: Idempotent Producers and Transactions (Effectively Exactly-Once) - Apache Kafka was built as a distributed log, and historically it provided at-least-once delivery as well (consumers read and commit offsets; if a consumer failed before committing, it would re-read messages, causing possible duplicates). However, Kafka introduced features to achieve exactly-once processing semantics within a Kafka pipeline starting from version 0.11. These features include idempotent producers and transactional messaging:
- Idempotent Producer: When enabled (
enable.idempotence=true), Kafka producers attach a sequence number to each message per partition and use a producer ID. This allows the Kafka brokers to automatically deduplicate any retried messages. For example, if a network glitch causes the producer to retry sending a message, the broker will recognize a duplicate sequence number and not double-write the message to the log. Idempotent producer mode guarantees that within a single producer session, messages will be written to Kafka exactly once even if retries occur (it covers the producer→broker leg of the journey). This already sets Kafka apart from many brokers - with RabbitMQ, a publish retry could result in duplicate messages unless you implement your own deduping. Worth noticing: this is exactly the angle on which the popular “smart broker - dumb consumer” slogan flips - on the dedup axis Kafka is the one with the smart producer, and the broker becomes a participant in dedup, not a passive log. (I unpacked that slogan more carefully in the companion article on Kafka vs RabbitMQ models.) - Consumer Transactions (Read-Committed Isolation): Kafka’s more powerful feature is the Transactions API. This allows a producer (or a consumer-producer application) to produce messages to multiple partitions atomically, and optionally to tie in the advancement of consumer offsets into the same atomic operation. In simpler terms, a consuming application can start a transaction, read some messages from Kafka, process them, produce some output messages to other Kafka topics, and then commit the transaction. The act of committing the transaction will make both the new output messages and the updated consumer offsets visible to others as a single unit. If the application crashes or rolls back, none of the output or offset updates become visible - so the input messages will be redelivered to another consumer (or retried on restart) and the partial output won’t be seen. This ensures that either the input messages are processed and the results sent exactly once, or not at all, preventing partial processing. To use this, consumers subscribe in read_committed mode, meaning they only see messages from transactions that were committed, and skip any aborted data.
- Example: Suppose you have Topic A → process → Topic B. With transactions, your app can consume a batch from A, do calculations, produce to B, and only commit the transaction (which includes “offset A up to X is processed” and the new events in B) if everything succeeded. If the app crashes midway, the transaction is aborted: no output appears on B, and the offsets are not marked as done, so another consumer will retry from the last committed offset. This yields an exactly-once processing of Topic A into Topic B (within Kafka). This is essentially what Kafka Streams (discussed below) uses under the hood.
- Limitations: Kafka’s exactly-once guarantees hold within the Kafka ecosystem - between Kafka topics (and with respect to Kafka’s own log and consumer mechanism). It does not magically make external side effects idempotent. If your Kafka consumer transaction includes, say, writing to a database or sending an email, Kafka cannot roll back those external actions if the transaction aborts. For instance, if you send an email in the middle of a transaction and then crash, Kafka will abort and redeliver the message later - and you’d send the email again unless you handled that in your application. Thus, Kafka’s transactions solve the “multiple processing or double publish” problem for Kafka topics, but end-to-end exactly-once still requires the application to handle external side effects via idempotency or other measures. Confluent’s docs and blog articles emphasize that “state changes in your application need to be committed transactionally with your Kafka offsets” to truly get exactly-once. In practice, that means if you are updating a database as a result of Kafka messages, you’d either use a connector that can participate in the transaction (some sink connectors try to do this two-phase commit with certain databases), or more commonly, you ensure the DB write is idempotent (so even if Kafka delivers the message twice due to a crash before offset commit, the second write does nothing new). Side effects, again, are the thing biting us at the end of the day.
Stepping back, the difference shakes out cleanly. RabbitMQ doesn’t offer built-in exactly-once delivery to consumers, so the recommended approach there is at-least-once plus idempotent handling at the application layer. Kafka does provide the tools for effectively-exactly-once processing in a pipeline, via idempotent producers and transactional consumers. If you follow the pattern and stay inside Kafka for the processing steps, each input event will result in exactly one output event even across crashes. Kafka’s durable retention also means a consumer can replay or re-check processed events, which is useful both for building exactly-once logic and for recovering from bugs in it. RabbitMQ discards messages once acked, so if something subtly broke in processing, you can’t ask the broker to replay older messages; you’d have to have requeued them at the time of failure.
Worth noting that Kafka’s advantage here is real but not unconditional. Achieving exactly-once with Kafka still requires careful design and pays a performance cost: idempotence and transactions add coordination and flushing overhead, which reduces throughput. Exactly-once isn’t a switch you flip in broker config; it’s a trade-off you commit to in application logic. As one expert put it, “Exactly-once semantics require careful construction of your application, assume a closed, transactional world, and do not support the case where people want exactly-once the most: side effects.” In a lot of real systems, designing for idempotency directly is both necessary and simpler. The honest one-liner is that exactly-once is at-least-once plus idempotence under the hood; Kafka just gives you better-shaped tools to build that.
So the practical split is this. RabbitMQ is at-least-once (duplicates possible) unless you add your own safeguards on top. Kafka is at-least-once by default, but lets you configure transactional exactly-once processing inside Kafka topics. If your use case actually needs that guarantee and you can absorb the complexity and performance cost, Kafka gives you stronger built-in support than RabbitMQ. The reason isn’t magic; it’s that Kafka’s commit-log-plus-offsets design makes idempotence and transactions more natural to bolt on, whereas RabbitMQ’s traditional queue model leaves the whole job to the consumer.
Kafka Streams: in-Kafka exactly-once made practical
Kafka Streams is a Java library (Scala-friendly) that lets you build stream-processing applications as ordinary client apps connecting to a Kafka cluster. There is no separate processing cluster to deploy alongside Kafka - you write a StreamsBuilder topology (filter, map, aggregate, join, window) and run it as a service. If you have ever used ksqlDB, you have used Kafka Streams under the hood.
The reason it earns a section here is that Kafka Streams is the cleanest practical realisation of in-Kafka exactly-once I know of. Setting processing.guarantee=exactly_once_v2 flips three things on at once: idempotent producers (no duplicate writes from retries), Kafka transactions (atomic writes to multiple topics), and transactional offset commits, where the consumer’s progress through the input topic is committed together with the output writes inside a single Kafka transaction. The practical consequence is straightforward: if the app crashes anywhere inside read → process → produce → commit, the entire transaction aborts. No output messages become visible to downstream read_committed consumers, the input offsets aren’t advanced, and the failed batch is simply redelivered. Either everything happened, or nothing did.
That is genuine exactly-once. Each input record produces its outputs and advances offsets exactly once, even across crashes. Kafka Streams also persists its local state (counts, windowed aggregates, joined tables) by replicating it to internal changelog topics, so a restarted instance rebuilds state from the same transactional log - the state and the offsets cannot drift apart.
The catch is the one this whole article keeps circling back to: this only works while everything lives inside Kafka. The moment your topology calls out (writes to a database, sends an email, hits an external HTTP API), Kafka cannot roll any of that back when the transaction aborts, and you’re immediately back in the inbox-and-idempotency world. Confluent’s own docs spell it out: “state changes in your application need to be committed transactionally with your Kafka offsets” to actually get exactly-once. If the state lives in Postgres, Kafka transactions alone don’t save you.
So Kafka Streams gives you a closed, transactional world where exactly-once is real. The price is that the world has to stay closed. That is a perfectly reasonable design - plenty of analytics, enrichment, and aggregation pipelines naturally fit inside it. For everything else, it is back to outbox + inbox + idempotency.
(For Python services, Quix Streams offers the same shape - stateful stream processing on Kafka with similar semantics - without leaving the Python ecosystem. Same idea, different language.)
Conclusion
The whole topic, when I lay it out for myself, comes down to a fight against side effects. Networks reorder, brokers retry, processes crash mid-action, and any of those would be harmless if there were no side effects to corrupt. Every framework we’ve built around this (at-least-once delivery, idempotency, dedup stores, outbox, inbox, XA, sagas, Kafka transactions) is a different price point on the same underlying trade-off curve.
The single heuristic I’d carry out of this writeup is: assume at-least-once at the wire, and design for exactly-once at the outcome. The diagram earlier in the piece is, more or less, the full decision space. The rest is just a question of which branch your specific problem actually lives on.
If a year from now I forgot the article and only remembered four words - two stores, side effects - I think I’d still get most decisions in this space approximately right. The patterns are the names we put on the trade-offs that fall out of those four words.
Glossary
1Delivery semantics-The promise a broker or pipeline makes about message delivery count: a message may be lost, retried, duplicated, or processed as one visible outcome depending on the chosen model.
2At-most-once-A delivery mode where a message is delivered zero or one time. It avoids duplicates, but a crash or network failure can lose the message permanently.
3At-least-once-A delivery mode where the system retries until the message is accepted. It protects against loss, but consumers must be ready for duplicates.
4Exactly-once-The desired outcome where each logical message changes the world once. In real distributed systems this usually means carefully designed effects, not a magic wire-level guarantee.
5Effectively exactly-once-A practical result where retries and duplicates may happen internally, but idempotency, deduplication, or transactions make the final business effect appear once.
6Side effect-Any externally visible change caused by processing a message: writing a row, charging a card, sending an email, publishing another event, or calling another service.
7Idempotency-A property of an operation where running it more than once has the same final result as running it once. It is the main application-level defense against duplicate delivery.
8Deduplication store-A durable record of message ids or idempotency keys that lets a consumer recognize repeated work and skip applying the same side effect again.
9Outbox pattern-A pattern where business data and an outgoing event are written in the same database transaction. A relay later publishes the event, keeping DB state and broker state in sync.
10Inbox pattern-A consumer-side pattern where processed message ids are stored before or together with the side effect. It turns duplicate deliveries into no-ops.
11Relay-The background process that reads pending outbox rows and publishes them to the broker. It may retry, so consumers still need duplicate handling.
12Acknowledgement (ACK)-A consumer’s signal to the broker that a message was accepted. If the ACK is missing after a failure, brokers such as RabbitMQ can redeliver the message.
13Offset-A Kafka consumer’s position in a partition log. Committing an offset records that the consumer considers messages up to that point processed.
14Idempotent producer-A Kafka producer mode where producer ids and sequence numbers let the broker drop duplicate writes caused by retries.
15Kafka transaction-A Kafka mechanism that can atomically publish records to topics and commit consumed offsets. It is strongest when the whole workflow stays inside Kafka.
16Read committed-A Kafka consumer isolation mode where downstream readers see only committed transactional records and skip aborted transaction output.
17XA / 2PC-A distributed transaction approach where a coordinator asks multiple resources to prepare and then commit together. It can provide atomicity, but adds latency and operational fragility.
18Saga-A way to coordinate a multi-step business flow through local transactions and compensating actions instead of one global transaction.
19Compensating action-A business-level undo step used by a saga. It does not erase the original side effect; it applies another action that balances it out.
20Closed transactional world-A boundary where every relevant state change participates in the same transaction system. Kafka Streams can approach exactly-once inside this boundary, but external APIs and databases break it.
References
- RabbitMQ vs Kafka Part 4 - Message Delivery Semantics and Guarantees - Jack Vanlightly
- How to choose between Kafka and RabbitMQ
- Why you cannot have Exactly-Once delivery in a distributed MQ : r/programming
- THEORY: Distributed Transactions and why you should avoid them (2 Phase Commit, Saga Pattern, TCC, Idempotency etc) · GitHub
- Ensuring Exactly-Once Delivery with RabbitMQ | Reintech media
- Idempotent API - by Neo Kim - The System Design Newsletter
- ActiveMQ - Should I use XA?
- What Is the CAP Theorem? | IBM
- When to use RabbitMQ or Apache Kafka - CloudAMQP
- Python stream processing made simple - Quix Docs
- RabbitMQ vs Kafka: Use Cases, Performance & Architecture | Upsolver