Introduction
When people talk about message-oriented middleware today, three names come up most often: Apache Kafka, RabbitMQ, and NATS. NATS has its own specifics - it started as a very lightweight, in-memory pub/sub broker focused on minimal latency, and with JetStream it later gained persistence and stream replay. Like the other two, NATS can be pushed into either of the roles I will describe below - a queue-style task transport or a streaming event log. But the clearest, most “textbook” representatives of the two opposing paradigms are RabbitMQ and Kafka: one was designed as a classic queue broker (think courier / commis voyageur), the other as a distributed commit log (think post-office pickup board). I will unpack both analogies properly when we get to the Kafka section, and use these two brokers as the running example throughout the article.
This article has two intertwined goals:
- Understand the underlying model. What Event-Driven Architecture really is, the difference between choreography and orchestration (broker vs. mediator), and the difference between a message and an event.
- Understand the difference between Kafka and RabbitMQ. What each was designed for, how their architectures actually look (exchanges and queues vs. topics and partitions, push vs. pull, transient delivery vs. durable log), and where each one naturally shines - including a concrete code-level walkthrough of why the difference matters when you sit down to build something.
There is a third, equally important thread - delivery guarantees (at-most-once, at-least-once, exactly-once, idempotency, dedup, outbox/inbox, XA, Kafka transactions). That topic deserves its own article, and I have written it as a companion piece - see Exactly-Once Delivery: the holy grail and the fight against side effects for the deep dive. I will reference the relevant pieces here, but the architectural side is what this article is about.
The narrative is meant to be visual and structured, so that by the end you have a coherent mental model of the difference and can confidently pick the right tool for a given problem.
One framing note before I dive in, because this tripped me up at first. When I say “sync” and “async” in this article, I do not mean the code-level keywords (async/await, threads, coroutines, channels). I mean the semantics of how information travels between components: either the sender waits for a reply before moving on (sync), or it fires the information off and keeps going (async). At the messaging layer those are really the only two options. Event-Driven Architecture is, by definition, the second one - events are always async, the publisher does not block on consumers. Synchronous coordination through messaging does exist - sending a command and waiting for the response (request-reply, RPC over a broker, sagas with synchronous steps) - but that is a separate conversation, and I will save it for its own article. For this one, hold the simple rule in mind: EDA = async semantics, and everything below follows from that choice.
Event-Driven architecture: mediator vs orchestrator (choreography)
Event-Driven Architecture (EDA) is an architectural style in which the components of a system exchange information through events. There are two main ways to organize the resulting event flows: broker / choreography and mediator / orchestration. With choreography there is no central controller - events simply propagate through the system, and each service reacts to them on its own. This is the broker topology: components broadcast events into a shared bus, and other components either react or ignore them. There is no central coordination, which improves flexibility and scalability but makes data consistency and error handling harder.
With orchestration a central mediator is introduced, which manages the event flow and coordinates the execution of multiple steps. This is the mediator topology. The mediator receives an event, knows the required sequence of actions (workflow), and dispatches commands to specific services or processors. In other words, the mediator acts as the orchestrator of a business process: it does not perform the business logic itself, but hands tasks out to executors and tracks their completion. This approach gives stricter control, simplifies error handling and ordering, but at the cost of tighter coupling between components, and it can become a bottleneck.
When do you use each? As a rule, choreography (broker) fits simple reactions to individual events, where one event requires very few actions from the system. There is no central decision-making node and components are as decoupled as possible. Orchestration (mediator), on the other hand, is needed when one event triggers a complex business process involving several steps and services - there a central coordinator makes it easier to guarantee that every stage runs. Both models are used in distributed systems: microservices may interact through a shared event bus (choreography) or through a dedicated orchestrator / saga. It is important to understand these patterns, because RabbitMQ and Kafka are most often used as an event broker (choreography), but they can also participate in orchestrations (for example, RabbitMQ is frequently used to coordinate tasks through an intermediary).
Message vs Event: what is the difference?
In distributed systems the terms “message” and “event” often overlap, but there is a subtle semantic difference. A message is the broader term: essentially any unit of data passed from one application to another is a message. A message usually implies an intent on the sender’s side to cause some action on the receiver - often this is the equivalent of a command or request. An event, by contrast, is a fact, a notification that something has already happened. An event signals a change or state in the system that has occurred and is published without expecting a specific response. For instance, in CQRS/DDD terms, sending a command is a message that asks for an action, while publishing an event is a notification that an action or change has already taken place.
Key differences: an event always denotes an immutable past fact (it has happened and cannot be undone), while a command-message represents a desired future action (which may be performed or rejected). When emitting an event, the source does not know or control who will receive it and how they will react - possibly many subscribers will simply log or further process it. When sending a command-message, the sender usually addresses a specific receiver or service and expects the task to be carried out. So a message is the general concept and may carry either a command or an event, while an event is a special kind of message that carries information about something that happened (typically delivered via a pub/sub model). Later I will show that historically RabbitMQ has been used more for command messages (jobs, tasks) between services, while Kafka has been used to broadcast events (a log of changes) to many consumers. In principle, however, both Kafka and RabbitMQ can carry either kind - the difference is mostly in the usage model.
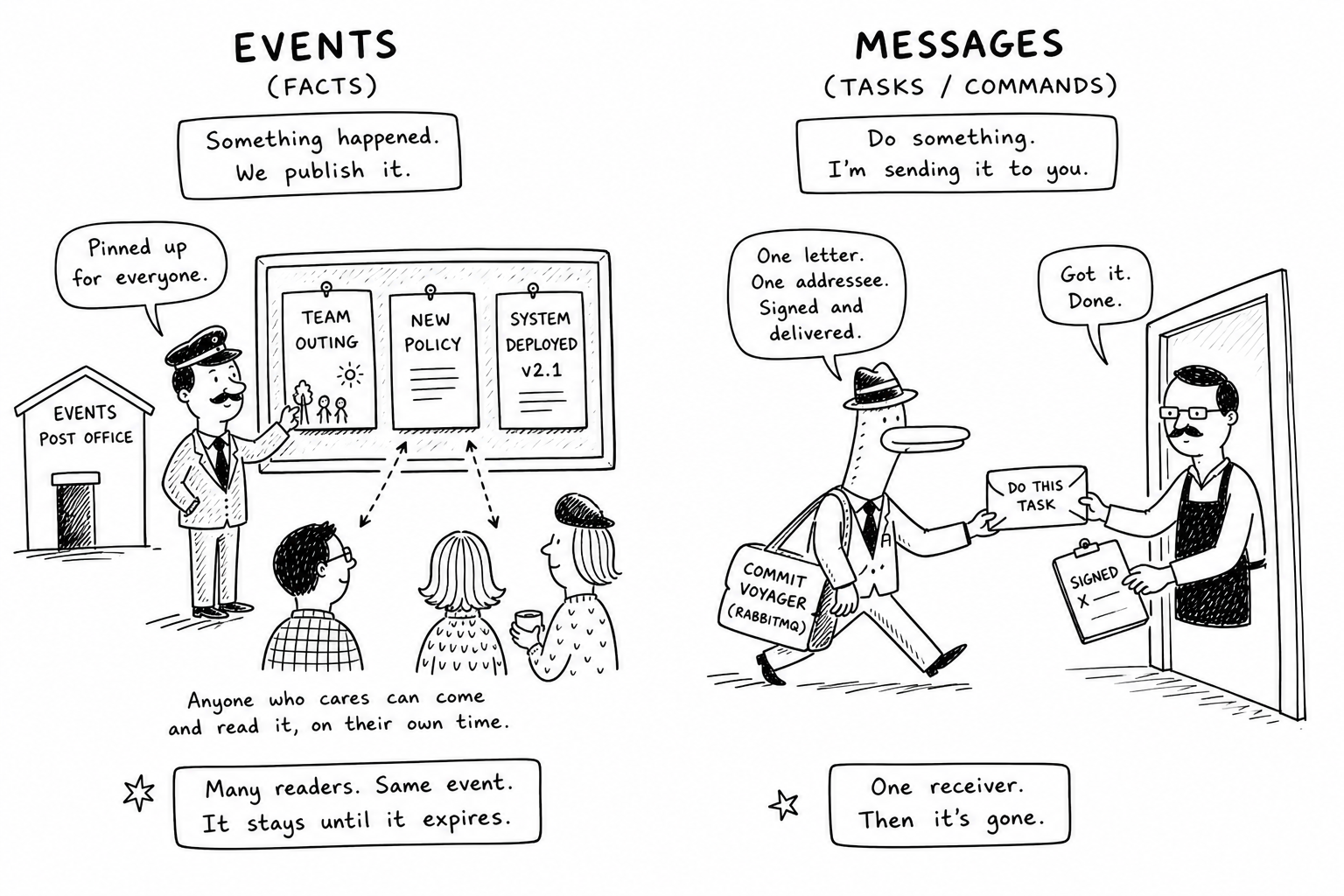
This distinction is not just terminological - it is the conceptual axis on which the whole RabbitMQ-vs-Kafka comparison turns. Tasks (commands) want a specific worker to do a specific thing, and once it is done, the work is over. Events are facts that the system records: the work, from the publisher’s perspective, is already done by the act of publishing, and any number of interested parties may then react. Hold this in mind as I walk through each broker.
RabbitMQ - purpose and architecture
RabbitMQ appeared in 2007 and was originally designed as a general-purpose message broker for reliable message delivery between applications over the AMQP protocol. It is written in Erlang and focuses on guaranteed delivery with rich routing capabilities. RabbitMQ has long been used in integration and SOA systems: it provides communication between microservices, processing of background jobs (task queues), and real-time messaging (e.g. payment processing).
RabbitMQ architecture: the broker is built around the concepts of exchanges (Exchange), queues (Queue), and bindings (Binding). Producers (senders) publish messages not directly to a queue, but to an exchange - essentially a virtual post office that decides which queues an incoming message should be routed to based on certain keys or rules. A queue is a buffer that stores messages until a consumer picks them up. Multiple consumers can be attached to a single queue, but a message is normally delivered to only one of them (the Competing Consumers pattern). RabbitMQ implements the “smart broker - dumb consumer” model: the broker actively pushes messages to consumers (push model) and tracks their state (acknowledgements), making consumption as simple as possible for the applications.
Example RabbitMQ architecture: a producer publishes a message to an Exchange, which routes it to the appropriate Queue based on a rule (e.g. by routing key). A consumer subscribed to that queue receives the message. The exchange acts as an intermediary (it can be of various types: direct, fanout, topic, etc.) for flexible distribution of messages across queues, while the queue guarantees ordered delivery to the consumer.
This architecture lets RabbitMQ support complex routing. You can configure exchanges of various types: direct (by exact key), topic (by pattern), fanout (broadcast to all bound queues), and so on - convenient for splitting different categories of messages into separate queues or addressing specific services. RabbitMQ also supports message priorities (you can assign a priority, and higher-priority messages in a queue are delivered first) - useful when critical messages must be processed ahead of others.
Delivery guarantees and acknowledgements: RabbitMQ is geared toward reliable end-to-end delivery. Once a consumer receives a message, it must send the broker an acknowledgement (ACK). Until then the message stays in the queue; if the consumer crashes or fails to ack in time, RabbitMQ redelivers the message to another receiver. This mechanic provides at-least-once delivery - the message will not be lost, but in case of a consumer failure it may be delivered more than once. For some scenarios you can enable auto-acks (messages are considered accepted as soon as they are received), which gives at-most-once (no duplicates, but a risk of loss on consumer failure). Thanks to these mechanisms RabbitMQ fits well for tasks that require guaranteed delivery of every message to its addressee (for example, queueing jobs for processing).
Beyond AMQP, RabbitMQ also speaks MQTT and STOMP out of the box (via plugins), which makes it a convenient single broker for IoT-flavoured workloads alongside ordinary service-to-service messaging. The honest tradeoff is that classic RabbitMQ was not designed for long-term storage and replay, and a single classic broker without special tuning typically pushes through tens of thousands of messages per second rather than millions. Horizontal scaling does exist (clustering, sharded queues, quorum queues), but it is less transparent than in Kafka.
For the comparison with Kafka below I will use RabbitMQ’s classic-queue baseline - not Stream Queues, which deserve their own caveat:
Apache Kafka - purpose and architecture
Apache Kafka was developed at LinkedIn and open-sourced in 2011 with a very different philosophy: it is a distributed streaming data platform, tailored for scalable processing of event streams. Kafka is written in Java/Scala and was designed for very high loads: it can ingest and process millions of events per second with minimal latency while still providing fault tolerance and durable storage of data. Conceptually, Kafka was framed as a distributed commit log - an ordered log of events to which you can both append new records and read previously written ones at any time. That made Kafka an ideal foundation for reactive, analytical, and event-driven systems where you need to both collect a stream of data (e.g. clickstream logs, telemetry, financial transactions) and let many consumers independently read and process this data in real time.
Kafka architecture: the key entities are topics (Topic), topic partitions (Partition), brokers, and consumer groups. A topic in Kafka is the analogue of a category or channel into which messages of a particular type are published. Kafka producers send messages directly to a specific topic (bypassing complex routing). Inside a topic, messages are stored not in a single queue but spread across partitions - multiple independent logs, each living on a different broker in the cluster. Each partition is an ordered, append-only log of messages persisted to disk. This split is what lets Kafka scale horizontally: different partitions of the same topic can be processed in parallel on different nodes, increasing throughput, while replication (copies of partitions stored on several nodes) provides fault tolerance.
Overall Kafka layout: producers write events into specific topics on a Kafka broker. Unlike a queue, messages in a topic are not deleted after being consumed. Instead Kafka keeps every record in a topic for a configured time (e.g. several days or weeks) or until a log size limit is reached. Consumers themselves request new messages from topics (pull model) and track how far they have read (offset). As shown in the diagram, several producers can write to different topics, while consumers (organized into groups) pull data from the topics they care about. The Kafka broker does not distribute messages to consumers itself - it simply stores and serves data on demand.
Kafka follows the “dumb broker - smart consumer” principle. The broker keeps almost no bookkeeping of who has read what; its job is to cheaply write the incoming message stream to disk (using sequential writes for high speed) and to hand the data out to consumers on request. The consumer is responsible for remembering its own offset (its position in the log) and for confirming processing by committing that offset (usually back into Kafka itself). This model means Kafka is pull-based (consumers fetch data when they are ready), in contrast to RabbitMQ’s push model. It solves the load-balancing problem nicely: a slow consumer simply reads with lag without affecting the broker, and fast consumers can read more and catch up. Producers in Kafka do not know whether their message has been processed - they just write into the log and move on.
The textbook way to put this is “queue vs. log”, but I find a different picture sticks better. Think of Kafka as a post office where notices get pinned up on a public board - say, an invitation to a team outing, or a notice about a new internal policy. The notice sits there. Anyone who cares - people from different teams, different departments, different jobs - can walk in, glance at the board, and read the same notice on their own time. The post office does not chase anyone down; it just keeps the notice up until the retention period expires. RabbitMQ, by contrast, is the courier - the commis voyageur - who is handed one specific letter and one specific addressee, walks straight to that person, hands it over, gets the signature, and the letter is gone from the system. The courier does not leave copies on a board; the post office does not run after anyone. That is the task vs. fact distinction made physical - RabbitMQ optimizes for delivering one specific thing to one specific person, Kafka optimizes for posting a fact and letting whoever cares come read it.

Storage and retention: because Kafka keeps the log around for the full retention window, each consumer reads the stream independently and can even connect later and replay events from the past. In RabbitMQ, by contrast, a classic queue removes a message as soon as it is acknowledged - it is oriented toward one-time delivery. This distinction is fundamental: Kafka was designed from the start as a durable event log, while RabbitMQ was designed as a mailbox from which a letter is picked up and disappears. (RabbitMQ’s Streams mode, as noted in the sidebar above, brings it closer to Kafka’s log-oriented model.)
Consumption model and scaling: Kafka consumers are typically organized into consumer groups. A group is a logical unit identified with some application or service. Kafka guarantees that each topic message will be delivered to exactly one instance within a group (giving queue semantics, but at the group level). If the group contains several instances, Kafka automatically distributes the topic’s partitions among them (each instance reads its own subset of partitions). This gives horizontal scaling of processing: you can add more consumers to a group and they will share the work. Different groups, meanwhile, consume the topic independently (pub/sub) - the same Kafka event can be processed simultaneously by several independent services. For example, a topic of purchase events can be read by one group to update inventory, by another for sales analytics, and by a third to send notifications, and Kafka makes sure every group sees every event. This combination of queue (within a group) and fan-out subscription (across groups) is a powerful mechanism for building large-scale event systems.
Performance: thanks to its design (sequential writes to disk, no immediate deletion) Kafka achieves very high throughput. Estimates suggest Kafka can handle millions of messages per second per cluster, while RabbitMQ is in the order of thousands or tens of thousands of messages/sec per node (reaching millions requires clustering and queue sharding). In benchmarks Kafka shows 10-15x higher throughput than RabbitMQ. Its average latency can be slightly higher at low load (because of disk writes), but at high load Kafka maintains low latency and does not “sag”, thanks to its distributed-system design. RabbitMQ can deliver very low latency at moderate volumes (the broker processes things in memory), but under extreme load its queues can become a bottleneck and latency grows. Overall, Kafka is optimized for high volume and end-to-end throughput, while RabbitMQ is optimized for minimal latency and guaranteed delivery in medium-volume scenarios.
Comparing them in code: the multi-consumer thought experiment
It is fun to talk about couriers vs. post-office pickup boards in the abstract. The conceptual difference really lands, though, when you sit down to write code for one specific scenario. Let me walk through one.
Imagine I have an event - "OrderPlaced" - and two services that both need to react to it independently: a notification service (sends the user a confirmation) and a business-logic service (updates inventory, triggers downstream workflows). Both want to read the same event.
On RabbitMQ. If I create one queue and bind both services to it as consumers, RabbitMQ will treat them as competing consumers. Each message in the queue gets delivered to exactly one of them, not both. The notification service might get the first event and the business-logic service the second, and so on - interleaved, never duplicated. There is no way to get “both services see every message” with a single queue, because that is fundamentally not what a queue does. The fix is to create two separate queues, bound to a fanout (or topic) exchange that copies each published message into both. Now each service has its own queue and reads its own copy. Conceptually, you are physically duplicating the message in order to get two independent consumers.
On Kafka. I create one topic - order-events - and stand up the two services with different consumer group ids: notification-svc and business-svc. Both subscribe to the same topic. Kafka delivers every event to both groups, and each group independently tracks its own offset in the topic’s append-only log. The notification service can sit at offset 1000 while the business-logic service is at offset 800; the messages are not physically duplicated, they are simply read independently. (Quick honest aside - I almost said “we partition by consumer”, but partitions are not the relevant axis here. Consumer groups are. Partitions matter for parallelism within a single group; the fan-out across groups is what consumer groups are for.)
This is why RabbitMQ feels “worse” for multi-consumption - not because of a bug or a missing feature, but because its core abstraction (the queue) is built around the opposite assumption: “this task should go to exactly one worker”. Kafka’s core abstraction (the log) starts from “this event is now part of the record; whoever wants to read it, can”. Both are correct for what they were built for.
A practical heuristic I keep:
- If I want to publish a fact and let the rest of the system react in whatever ways it wants - Kafka.
- If I want to hand a job to one specific worker and care about that worker’s completion - RabbitMQ.
Combining the two in practice
The more interesting answer in a real system is usually not to pick one. The two tools sit on different axes of the problem space, and any non-trivial backend tends to use both: RabbitMQ for immediate commands between services (where instant reaction and per-message acknowledgement matter - “reserve this item”, “charge this card”, “send this email”); Kafka for general event logging and data exchange for analytics, audit, ML pipelines, and any workflow that wants the same stream of facts replayed independently by several consumers.
The same logic extends to NATS - with JetStream it can play either role too, with its own latency and footprint trade-offs. The interesting question is rarely “which broker”; it is “which paradigm for which slice of the system”. The concrete e-commerce pairing is worked out in the conclusion below.
Conclusion
Kafka and RabbitMQ solve similar problems - passing messages between components - but from different angles. RabbitMQ is a classic message broker, focused on guaranteed delivery and complex routing for service integration. Kafka is a distributed event log, providing a scalable data stream for analytics and repeated consumption.
When choosing between them I lean on the system’s requirements:
- Do you need multiple independent consumers of the same data stream and storage of events for replay? Then Kafka is the obvious candidate, since it is designed for event streaming and scales to enormous loads.
- Do you need fast point-to-point delivery of messages between components (e.g. tasks for execution) with acknowledgements? Then RabbitMQ tends to be more convenient, especially if you need complex routing or message prioritization.
- Scalability: Kafka is easier to scale horizontally - by adding brokers and partitions. RabbitMQ can also work in a cluster, but a single classic queue scales vertically (on one node), so you have to split work across multiple queues by hand (or use the newer quorum / stream queues for a similar effect). In very high-load systems (as at large internet companies) Kafka is often preferred thanks to its simple-broker, distributed-log architecture.
In real projects the two are often used together, each playing to its strengths. For example, an e-commerce ordering system can use RabbitMQ to orchestrate execution of a specific order (with commands like “reserve item”, “charge payment” - instant processing and per-step delivery guarantees). In parallel, all events (order created, payment processed, item shipped) are published to Kafka for analytics, audit, machine learning, and other services that need historical and repeated views of those events.
So RabbitMQ vs Kafka is not a question of “which is better”, but of fitness for purpose. Once you understand their architectural differences - exchange/queue vs. log topic/partitions, push vs. pull, transient vs. durable storage, competing consumers vs. consumer groups - you can make a well-grounded choice for your requirements and even combine them.
There is one more layer underneath all of this - what happens on the wire when these messages start being retried, redelivered, deduplicated, and committed across more than one storage at once. That is the delivery-guarantees story, and it has its own dedicated piece: Exactly-Once Delivery: the holy grail and the fight against side effects.
Glossary
1AMQP 0.9.1-The original wire protocol RabbitMQ was built around: a flexible publisher / exchange / queue / consumer model with rich routing rules. Most general-purpose RabbitMQ clients speak it.
2MQTT-A lightweight pub/sub protocol popular for IoT and constrained-bandwidth scenarios. RabbitMQ supports it via a plugin.
3STOMP-A simple, text-based messaging protocol; useful for quick integration from languages or tools without a native AMQP client.
4Exchange types-RabbitMQ’s routing primitives: direct (exact routing key), topic (pattern-matched key), fanout (broadcast to all bound queues), headers (route by message headers).
5Quorum queue-RabbitMQ’s modern replicated queue type based on the Raft consensus protocol; replaces classic mirrored queues for high-availability setups.
6Stream queue-RabbitMQ’s append-only, replayable log type, conceptually closer to a Kafka topic. Best performance is reached over the dedicated Streams protocol, not AMQP 0.9.1.
7Partition-Kafka’s unit of parallelism inside a topic: an ordered, append-only log on a single broker. A topic’s partitions can be processed in parallel by different consumers.
8Offset-A consumer’s position inside a partition’s log. Each consumer (or consumer group) tracks its own offset and advances it as it reads.
9Consumer group-A logical group of Kafka consumers identified by a group id. Kafka guarantees each message in a topic is delivered to exactly one member of a group; different groups consume the topic independently.
10Replication factor / ISR-How many copies of a partition Kafka keeps across brokers, and the subset of those replicas currently in-sync with the leader. The basis of Kafka’s fault tolerance.
11Push vs pull-Two delivery models. RabbitMQ pushes messages to consumers as soon as they arrive; Kafka requires consumers to pull (fetch) records when they are ready. Pull naturally absorbs slow consumers without backpressure on the broker.
12Competing consumers-A pattern where several consumers attach to the same queue and each message is delivered to exactly one of them. RabbitMQ’s default model for a single queue.
13Idempotent producer-A Kafka producer mode (enable.idempotence=true) where retries cannot create duplicates: each message carries a producer id and a per-partition sequence number, and the broker drops duplicates automatically.
14At-most-once / at-least-once / exactly-once-The three classic delivery semantics. At-most-once may lose messages but never duplicates; at-least-once never loses but may duplicate; exactly-once is the holy grail, covered in the companion article.
15Outbox / Inbox pattern-Application-level patterns that pair a database transaction with message publishing or consumption. The outbox makes “save state + publish event” atomic; the inbox deduplicates incoming messages on the consumer side.
16Saga-A pattern for coordinating a multi-step business process across services without a distributed transaction, using either choreography (events) or orchestration (a central coordinator) and compensating actions on failure.
17XA / 2PC-A classical distributed-transaction protocol (two-phase commit) for atomic commits across multiple resource managers. Powerful but brittle, and unfashionable in modern microservice systems.
18Backpressure-The mechanism by which a slow downstream component signals an upstream producer to slow down. Kafka’s pull model and RabbitMQ’s flow control are two different ways to handle it.
19Replay-Reading already-consumed messages again. Native in Kafka (within the retention window, by rewinding the offset) and possible with RabbitMQ Streams; not possible with classic RabbitMQ queues, where ack’d messages are gone.
20Retention-How long a Kafka topic (or RabbitMQ Stream) keeps records before they become eligible for deletion. Configurable by time, by size, or both.
Sources
The core facts and comparisons come from official materials and authoritative reviews: Microsoft and 3Pillar on EDA topologies, community write-ups on the message-vs-event distinction, AWS and Confluent documentation on RabbitMQ vs Kafka differences, the CloudAMQP blog (2025) with hands-on observations, and Jack Vanlightly’s detailed treatment of delivery guarantees. These sources, alongside practical experience, helped shape the comparison above.
- Orchestration vs Choreography | Camunda
- RabbitMQ vs Kafka: Use Cases, Performance & Architecture | Upsolver
- Apache Kafka vs. RabbitMQ: Differences & Comparison · AutoMQ/automq Wiki · GitHub
- Apache Kafka vs. RabbitMQ: Comparing architectures, capabilities, and use cases
- Introduction to Kafka consumers | Red Hat Developer
- RabbitMQ vs Kafka Part 4 - Message Delivery Semantics and Guarantees - Jack Vanlightly
- When to use RabbitMQ or Apache Kafka - CloudAMQP